PDF を実際に読むよりも、スクロールすることに多くの時間を費やしていると感じたことはありませんか?これらの長くて複雑な文書内で特定の情報を見つけるのは、最初は難しいかもしれませんが’私たちのヒントに従えば、それほど複雑ではありません。この記事では、 ’ここでは、PDF の使用効率を向上させるいくつかの方法、つまり次の方法を見ていきます。
- 組み込みツールを使用して PDF を検索する方法。
- PDF を OCR で検索可能にする方法。
- ボーナス PDF 検索のヒント–最後まで読んでください!
組み込みツールを使用して PDF を検索する方法
ほとんどの PDF 編集ソフトウェアには PDF 検索バーが装備されており、通常、Windows では Ctrl+F キーボード ショートカット、Mac では Cmd+F でアクセスできます。一見シンプルな機能である検索バーは、 完全または部分的な単語や語句を即座に検索でき、テキスト内で見つかった一致を強調表示するため、驚くべき威力を発揮します。
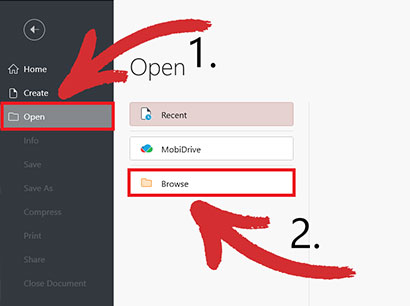
’これまで PDF ソフトウェアを使ったことがなくても、PDF Extra とその直観的なユーザー インターフェイスを使えば大丈夫です。 PDF を検索するには:
1. アプリを起動します。
2. 希望のファイルを開きます。
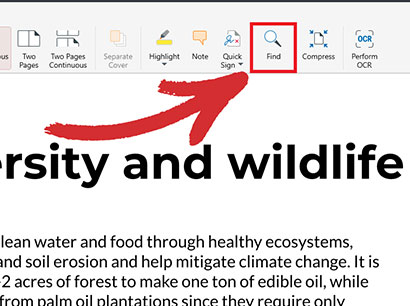
3. 虫眼鏡アイコンをクリックするか、Ctrl+F を押します。
4. 検索したい単語または語句を入力します。見つかった単語や語句は黄色でハイライト表示されます。
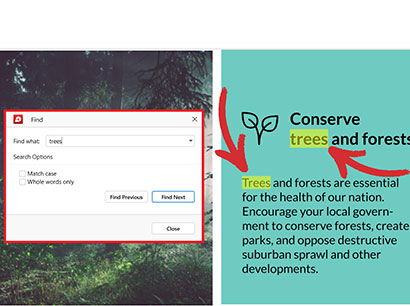
ヒント : 部分検索 (つまり、不完全な単語) の場合は、検索バーにテキストを入力するだけで十分です。単語に大文字が含まれている場合は、大文字で書き、 “にチェックを入れます。 大文字と小文字を区別する ”オプション。もしあなたが’特定の単語やフレーズを探している場合は、 “をチェックしてください。 単語全体のみ ”オプション。
5. 現在のページに一致するものが表示されない場合は、 “をクリックします。 前を検索 ”または“ 次を検索 ”より広いレベルで PDF 検索を実行します。
PDF 検索エンジンの有効性は、ドキュメントのテキスト抽出とインデックス作成の品質に大きく依存することに注意してください。 ’ 「スキャンされた PDF では機能しません。OCR が–光学式文字認識–が登場します。
作り方OCR による検索可能な PDF
あなたは’おそらくこれまでに経験したことがあるでしょ– Web からフォームをダウンロードすると、それが’スキャンした画像を使用して’いかなる方法でも検索または編集することはできません。このような場合、信頼できる OCR ツールを自由に利用できることが非常に役立ちます。 OCR とは何ですか? OCR を使用して PDF を検索する方法は?
光学式文字認識テクノロジーは、スキャンしたテキスト (ピクセル) を実際の検索可能なコンテンツ (文字) に変換します。簡単に言えば、PDF の OCR は象形文字を平易な英語に変換するようなものです–プログラムは文書の画像をスキャンし、個々の文字を認識して、検索可能なテキストに変換します。つまり、 スキャンしたドキュメントに OCR を適用すると、 内蔵の PDF 検索ツールを通常のテキストベースの PDF であるかのように使用できるということです。
多くのソフトウェア アプリケーションやオンライン ツールは OCR 機能を提供しています。その中には、市場で最高の光学式文字認識ソフトウェアが装備されている PDF Extra があり、 ワンクリックで最大 98% の精度が得られます 。
ドキュメントを OCR するには:
1. アプリを起動します。
2. ホームメニューから“に移動します。 ツール ” → “ テキストを認識 ” 。
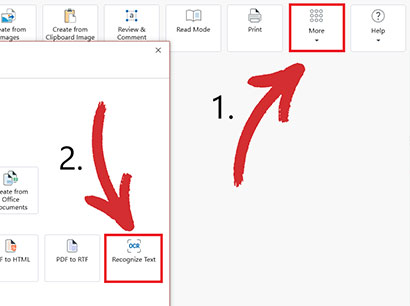
3. OCR したい文書を開きます。
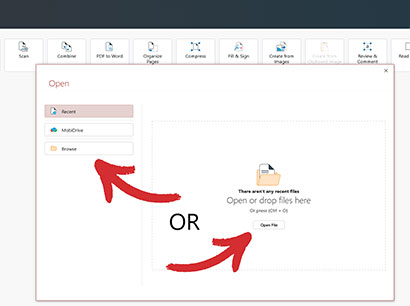
4. 最良の結果を得るために、OCR するページ数と文書内に存在する言語の数 (最大 3 つ) を選択します。
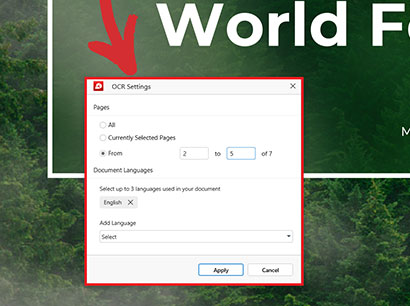
5. “をクリックします。 適用 ”選択を確認します。
6. Ctrl+F を押して PDF を単語検索します。
ボーナス: ブックマークを使用すると、すばやく検索できます
単語検索 PDF 機能は特定の用語を正確に特定するために不可欠ですが、ブックマークは PDF ナビゲーションに対する補完的なアプローチを提供します。ブックマークは、文書内に配置できるデジタル付箋と考えてください。これにより、特定のセクションに簡単にジャンプできます。これは、セクションや章が明確に定義されている長い PDF の場合に特に役立ちます。
ここでは、PDF Extra がさらに一歩進んでいます。多くの PDF リーダーは基本的なブックマーク機能を提供しますが、 PDF Extra はマルチレベルのブックマーク システムを備えており、これにより、PDF リーダー内にサブカテゴリを作成できます。ブックマーク。以下に、両方のブックマーク タイプの使用方法に関するいくつかのヒントを示します。
- メインレベルのブックマーク : これらは章の見出しと考えてください。主要なセクション (はじめに、方法論、結論など) のブックマークを作成します。
- サブレベル ブックマーク : より細かく制御するには、サブレベル ブックマークを追加します。これらは、章または他のものの中のサブセクションである可能性があります。
PDF Extra 内にブックマークを追加するには:
1. アプリを起動します。
2. ホームメニューから“に移動します。 ツール ” → “ テキストの編集&画像 ” 。
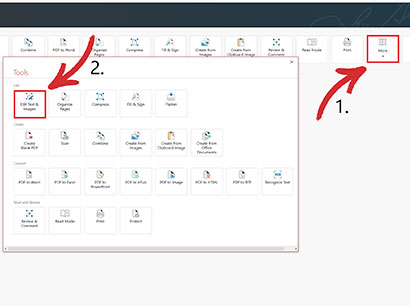
3. ブックマークを配置するドキュメントを開きます。
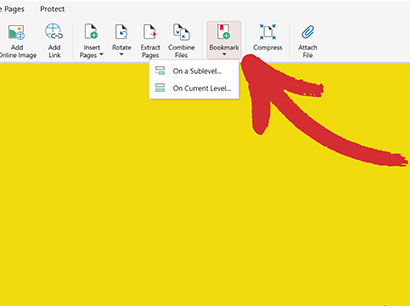
4. “をクリックします。 ブックマーク ”をクリックして、現在のレベルに作成するかサブレベルに作成するかを選択します。
5. 必要な数のブックマークをすばやく並べ替え、名前変更、追加、削除します。
6. ブックマークを選択して、文書の特定のセクションにジャンプします。
作成したブックマークには、 “から簡単にアクセスできます。 コンテンツ ” PDF Extra 内のパネルは、従来の PDF 検索方法の便利な代替手段として使用できます。ブックマークをクリックするだけで、ドキュメントの対応するセクションにジャンプします。

最終的な考え
要約すると、次のとおりです。必要なものを見つけるための 2 つの信頼性の高い教科書 PDF 検索方法:
- 内蔵検索 : 個々のファイル内の単語や語句をすばやく検索します。 Ctrl+F を押します。
- 光学認識 : OCR を適用することで、スキャンした PDF を検索可能にします。
これらのメソッドをブックマークと組み合わせると、 ’多くの時間とフラストレーションを節約し、一晩で生産性レベルを向上させる完璧なコンテンツ検索レシピを手に入れました。言葉狩りを楽しんでください。また次回まで!